We now arrived at the last post of this series about Domain-Driven Design (DDD) patterns…
DDD Concepts and Patterns – Service and Repository
In the previous posts of this series about domain driven design (DDD) concepts and patterns, I introduced some of the building blocks of a domain model: Entities, Value Objects, and Factories. Today I would like to extend this list with the Service and Repository Patterns.
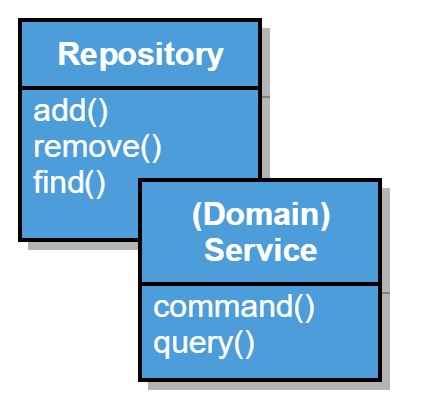
(Domain) Services are stateless objects that contain logic which cannot reasonably put on an entity or value object. These could be a complex calculation that needs input from multiple domain objects for example.
Most software systems need to persist data somehow. In DDD repositories are used to access persistent storage. They provide access to data using the metaphor of a library.
Services
Not every element or concept in a domain has attributes. Probably it only describes a logic or rule that gets data from other objects. For such cases, DDD proposes to model a (domain) service.
Domain services are stateless objects with methods (commands or queries) that take domain objects as arguments. They don’t need to be created (instantiated) by a factory because of their statelessness. Therefore we can use them by just passing the correct parameters to their methods.
For example, let us consider the addition of an item to the basket of a webshop. The business requires that baskets contain only products which are available in our inventory. Before adding a product, we need to check the inventory. This logic doesn’t fit well on the basket entity’s add method because we don’t want it to depend on the inventory. Also, other baskets could already contain the item too. However, it still is a business rule that we would like to express in the domain. Therefore we create a domain service which counts how many items of the product are in the baskets and checks if the inventory has more than this amount available.
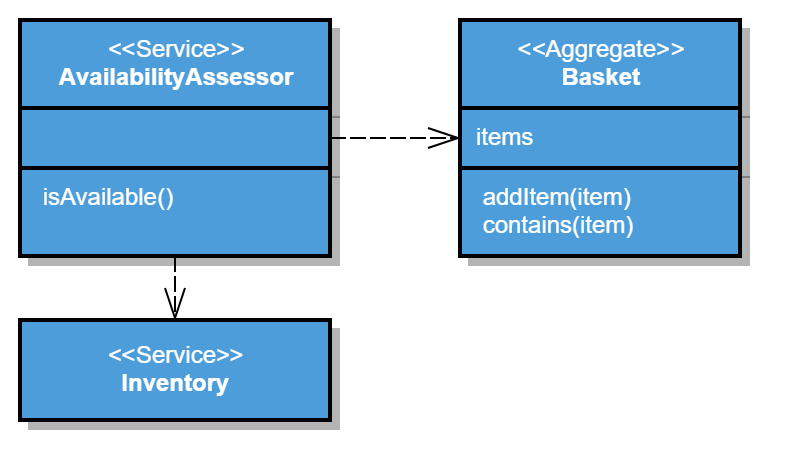
The AvailabilityAssessor nicely encapsulates the business rule, and we can remove responsibility and a dependency from the basket.
Repository
Repositories in DDD are used to access data from persistent stores. In contrast to many persistence libraries which use the language of databases like save and load, repositories use a library or set metaphor. Save is called add, load methods are getter or finder and delete becomes “remove”.
Below is a simple java interface of a repository following these conventions.
public interface AddressRespository {
void add(Address address);
void remove(Address address);
List<Address> findByStreetName(String streetName);
}
The add-method is used for new objects only. When we remove an object from the repository, we should delete it from the underlying persistence store.
Modifications are not the concern of repositories. From a domain perspective, we assume that all changes are persisted automatically. The pattern states that we should handle transactions in the application layer, not the domain.
We don’t need a repository for every entity or value object. Instead, repositories handle groups of domain objects together. These groups are called aggregates which is another tactical design pattern in DDD which I will introduce in the next post of this series.
Reconstitution
Eric Evans writes in his original DDD book [Eva04] that populating the domain object with data from the persistence should not be implemented in the repository but the factory. First I was skeptical about this statement. Why introduce another indirection and complicate the system?
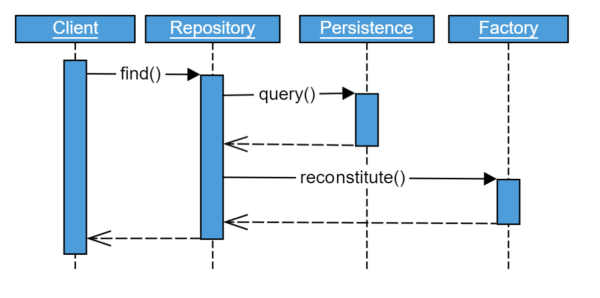
There are many different ways to store data to persistence like tables in relational DB, documents in a NoSQL-DB or events in event sourcing system. I think in those cases where we have some generic representation of the data in persistence like events or key-value pairs it feels natural to pass them to the factory for reconstitution.
However, if we load the data into specific objects already from the persistence how do we pass them to the factory? The factory shouldn’t depend on the persistence implementation. Therefore we cannot pass the data objects to it. We could use simple data types, add another interface or copy the data to a generic structure probably. I think it depends if this effort is worth the gained separation of the reconstitution concern.
Wrap Up / Final Thoughts
When some domain element or concept doesn’t fit on a domain object, the domain service pattern can be used. By keeping those services stateless their usage is simple. It could be tempting to build many services that hold big parts of the logic. This practice is not recommended though because data is split from the logic which complicates clients.
I found the Repository pattern very compelling because it separates persistence concerns from the domain. While writing business logic, I don’t want to think constantly of when to commit or what to do on a rollback. Things like these should be handled when writing higher-level workflow logic.
[Eva04] Eric Evans: Domain-Driven Design – Tackling Complexity in the Heart of Software (homepage)Frühere Beiträge